

The European Commission has put forward a draft legislation framework for a coordinated approach on the human and ethical implications of AI. Explore our AI Risk insights and what this might mean for your organisation.
Background
The first-ever wide-ranging legal framework proposal on AI is finally out. The EU has proposed new rules and actions for excellence and trust in AI used for mass surveillance or for ranking social behaviour. Organisations developing AI could face fines as high as 6% of global revenue if they fail to comply with new rules governing the software applications. The legal framework will apply to enterprises based anywhere as long as the AI system affects people located in the EU.
Overview
So, what does this mean for the enterprise from an AI deployment perspective? A lot, infact. AI systems are now classified as low, medium & high risk; enterprise AI use cases including recruitment selection, credit scoring & customer service need specific controls in place; voluntary codes of conduct as well as regulatory sandboxes are recommended to facilitate responsible innovation.
Specific recommendations include provisioning:
- Risk assessment and mitigation systems
- Governance of training data
- Audit trails for results
- Decision provenance for compliance
- Information dissemination for end-users
- Human-in-the-loop oversight measures and of-course
- Security and accuracy
Why is this important?
If you choose to deploy an advanced chat-bot or automate hiring or indeed use algorithms for credit scoring, you need to comply with the new regulation when it goes live.
While there are several obligations in the 108 page proposal, Article 11 on technical documentation is of particular interest. These include documenting the methods and steps performed for the development of the AI system, pre-trained systems or tools provided by third parties and how these have been used, integrated or modified by the AI developers.
Also of interest are the key design choices including assumptions made, details of the system architecture and integrated software components. The regulation also mandates documenting how you develop, train, test and validate the AI system, training methodologies and techniques and the training data sets used.
From a data governance perspective, information about the provenance of those data sets, their scope and main characteristics; how the data was obtained and selected; labelling procedures (e.g. for supervised learning), data cleansing methodologies (e.g. outliers detection) are mandated.
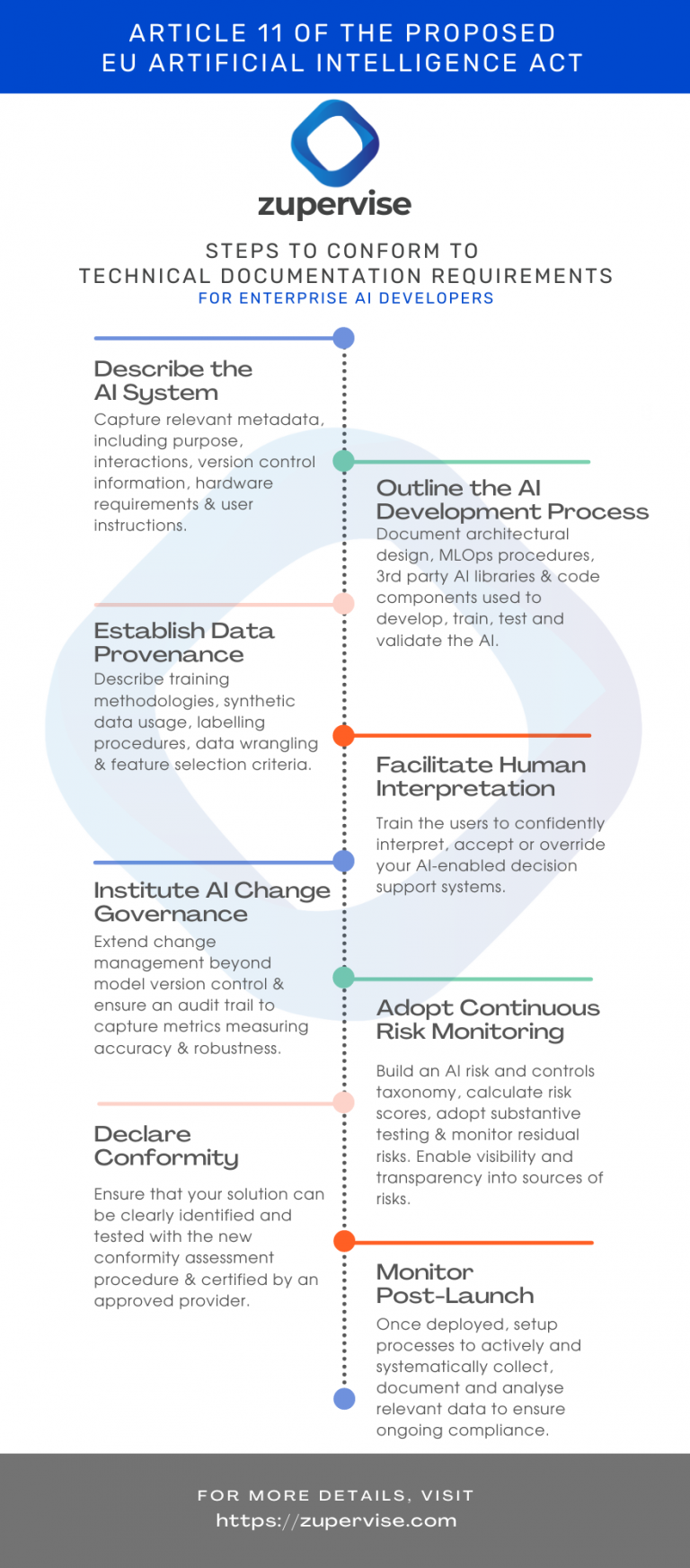
Recommendations
This is now the best time to act quickly and focus on building new capabilities:
- The creation, maintenance and validation of an enterprise-wide AI artefact inventory;
- The alignment of algorithmic impact assessments with supervisory guidance and business objectives;
- The monitoring of AI policy compliance and data governance standards, as well as audit trails.